Explosion combinatoire¶
La phobie du développeur doit être la complexité. Que cette complexité soit la complexité temporelle/spatiale du code à exécuter (quelle est la durée d’exécution, et combien de ressources sont mobilisées ?), ou la complexité d’écriture du code (combien de fonctions, de classes, de procédures dois-je implémenter ?).
Une grande complexité apparaît surtout quand il existe une dépendance (réelle ou supposée) entre les entrées de notre programme. Une façon de réduire la complexité d’écriture d’un algorithme est donc d’identifier cette dépendance et de l’éliminer. C’est la stratégie du diviser pour régner qui consiste à diviser un problème en sous-problèmes indépendants les uns des autres pour en faciliter la résolution. Une manière d’éliminer les dépendances non désirables est d’implémenter une interface entre les sous-problèmes.
Prenons un exemple pour mieux comprendre.
Convertisseur¶
Supposons que vous décidiez d’implémenter un script qui permette de convertir des fichiers csv/json/parquet/avro en csv/json/parquet/avro (pour l’intégrer dans un ETL fait maison par exemple).
Si le script a été écrit en Python, vous exécutez par exemple :
python convertor.py source.csv target.json
Pour convertir un fichier source.csv en target.json
Si par exemple le fichier source.csv ressemble à ça :
col1,col2,col3
"test","1","10"
"test2","2","20"
Le fichier target.json généré par le script ressemblera à ça :
[
{"col1": "test", "col2": "1", "col3": "10"},
{"col1": "test2", "col2": "2", "col3": "20"}
]
Voici un exemple de ce qu’il NE faut surtout PAS faire :
from enum import Enum
import os
import sys
class FileExtension(Enum):
csv: str = "csv"
json: str = "json"
avro: str = "avro"
parquet: str = "parquet"
class Convertor():
def convert(self, source_name: str, target_name: str):
source_extension = self._get_extension(source_name)
target_extension = self._get_extension(target_name)
print(f"Convert {source_extension.value} to {target_extension.value}")
#A NE PAS FAIRE !!!
if source_extension == FileExtension.csv and target_extension == FileExtension.json:
#TODO
...
elif source_extension == FileExtension.csv and target_extension == FileExtension.avro:
#TODO
...
elif source_extension == FileExtension.csv and target_extension == FileExtension.parquet:
#TODO
...
elif source_extension == FileExtension.json and target_extension == FileExtension.csv:
#TODO
...
elif source_extension == FileExtension.json and target_extension == FileExtension.avro:
#TODO
...
elif source_extension == FileExtension.json and target_extension == FileExtension.parquet:
#TODO
...
elif source_extension == FileExtension.parquet and target_extension == FileExtension.csv:
#TODO
...
elif source_extension == FileExtension.parquet and target_extension == FileExtension.json:
#TODO
...
elif source_extension == FileExtension.parquet and target_extension == FileExtension.avro:
#TODO
...
elif source_extension == FileExtension.avro and target_extension == FileExtension.csv:
#TODO
...
elif source_extension == FileExtension.avro and target_extension == FileExtension.json:
#TODO
...
elif source_extension == FileExtension.avro and target_extension == FileExtension.parquet:
#TODO
...
else:
raise NotImplementedError()
def _get_extension(self, filename: str) -> FileExtension:
_, extension = os.path.splitext(filename)
return FileExtension[extension.strip(".")]
if __name__ == "__main__":
Convertor().convert(sys.argv[1], sys.argv[2])
Avec cette façon de procéder, vous avez 4x3 = 12 procédures de conversion à écrire. Je tire un format parmi « csv », « json », « avro » et « parquet », puis j’en tire un autre parmi les formats non encore tirés (on suppose que personne ne demandera de convertir du csv en csv). Vous avez d’abord 4 choix possibles, ensuite 3. Le nombre de choix possibles est donc 4x3 = 12. Pour les plus curieux : si « n » est le nombre de formats à gérer, alors n*(n-1) sera le nombre de procédures à écrire (https://fr.wikipedia.org/wiki/Arrangement). La complexité d’écriture n’est certes pas exponentielle, mais polynomiale. Toutefois, le polynôme est un degré trop grand par rapport à ce que l’on peut faire.
Vous pouvez vous dire : ce n’est pas si grave, 12 procédures, c’est encore humainement possible. Mais supposons que demain vous deviez aussi gérer les formats « orc ». Vous n’auriez plus 4x3=12 procédures, mais 5x4=20 procédures, soit 8 nouvelles procédures à écrire. Supposons ensuite qu’après demain vous deviez aussi gérer le format « tsv », vous n’auriez plus 5*4=20 procédures mais 6x5=30 procédures à écrire, soit 10 nouvelles procédures à écrire. Pour chaque nouveau format à gérer, vous aurez plusieurs nouvelles procédures à écrire. Et plus le nombre de procédures existantes est grand, et plus le nombre de nouvelles procédures à écrire à chaque nouveau format sera grand (pour les curieux : si « n » est le nombre de formats existants, rajouter un nouveau format demande d’écrire 2 x n nouvelles procédures).
En écrivant le code de cette façon, vous avez supposé (peut-être inconsciemment), que la procédure pour créer un fichier target .json dépendait de l’extension du fichier source. Que pour écrire un .json, vous deviez savoir à quoi ressemble le fichier source que vous devez lire. Mais ce n’est pas le cas. Et s’en rendre compte vous aurez économisé et vous économisera de grandes souffrances.
Il s’agit de diviser pour régner : de résoudre le problème d’écriture de la cible indépendamment du problème de lecture de la source. Le simple fait de poser le problème en ces termes devrait vous faire entrevoir un début de solution.
Ma proposition :
from enum import Enum
import os
import sys
class FileExtension(Enum):
csv: str = "csv"
json: str = "json"
avro: str = "avro"
parquet: str = "parquet"
class Convertor():
def convert(self, source_name: str, target_name: str):
source_extension = self._get_extension(source_name)
target_extension = self._get_extension(target_name)
print(f"Convert {source_extension.value} to {target_extension.value}")
#mieux en terme de complexité
#on lit
data: list[dict] = None
if source_extension == FileExtension.csv:
#TODO
data = ...
elif source_extension == FileExtension.json:
#TODO
data = ...
elif source_extension == FileExtension.avro:
#TODO
data = ...
elif source_extension == FileExtension.parquet:
#TODO
data = ...
else:
raise NotImplementedError()
#PUIS on écrit
if target_extension == FileExtension.csv:
#TODO
...
elif target_extension == FileExtension.json:
#TODO
...
elif target_extension == FileExtension.avro:
#TODO
...
elif source_extension == FileExtension.parquet:
#TODO
...
else:
raise NotImplementedError()
def _get_extension(self, filename: str) -> FileExtension:
_, extension = os.path.splitext(filename)
return FileExtension[extension.strip(".")]
if __name__ == "__main__":
Convertor().convert(sys.argv[1], sys.argv[2])
La complexité n’est plus polynomiale de degré 2 (n x (n-1)) mais de degré 1 (2 x n). Pour 4 formats, cela ne fait peut-être pas une grande différence. Dans la version corrigée, il faut écrire 8 procédures, au lieu de 12. Mais dans le cas où l’on ajoute un nouveau format, il faudra rajouter uniquement 2 nouvelles procédures (une pour la lecture et une pour l’écrite), et non plus 2 x n nouvelles procédures. Ainsi, si demain vous voulez gérer également les formats orc et tsv, vous n’aurez plus que 12 procédures au lieu de 30 dans votre code.
La transformation du problème peut être visualisée de cette façon. Chaque arête représente une procédure à implémenter dans le script.
La 1ère façon de faire :
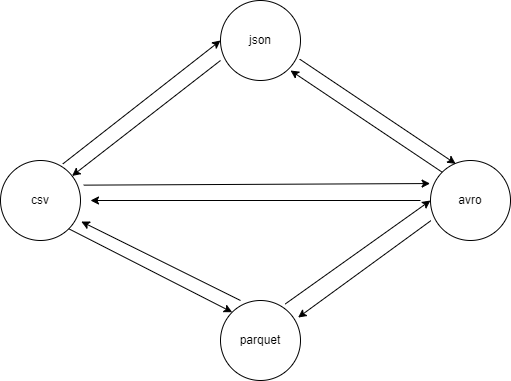
La 2ème :
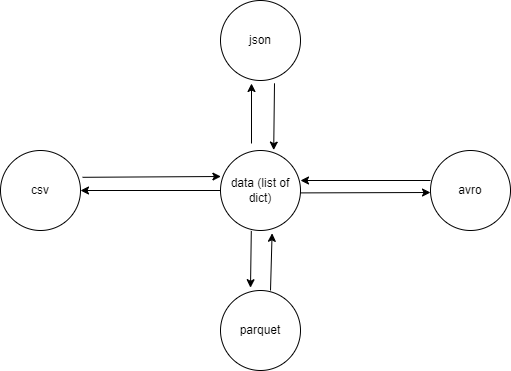
Le nœud du milieu s’appelle « une interface », et permet d’éliminer la dépendance entre les nœuds. Les nœuds ne sont plus dépendants que de l’interface. Par exemple, un protocole réseau bien défini, comme le HTTP, est une interface entre les différents nœuds du web. Un site web n’a qu’à implémenter correctement le HTTP pour être sûr d’être compris par tous les navigateurs, même ceux dont il n’a pas connaissance. Et les navigateurs qui implémentent correctement le HTTP, de leur côté, seront compatibles avec tous les sites web qui l’implémentent correctement, même ceux qui n’existent pas encore.